

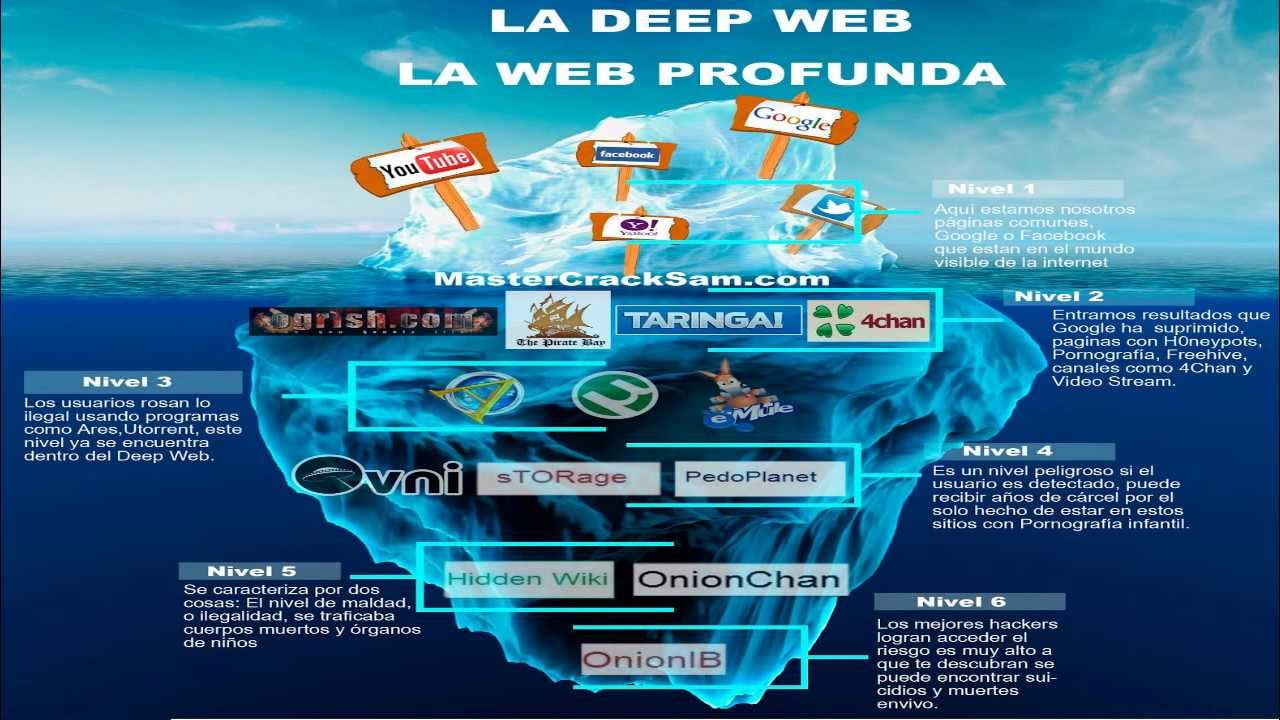
Se conoce como Internet Profunda o Internet Invisible (en inglés: Deepweb, Invisible Web, Deep Web,Dark Web o Hidden Web) a todo el contenido de Internet que no forma parte del Internet Superficial, es decir, de las páginas indexadas por las redes de los motores de búsqueda de la red. Esto se debe a las limitaciones que tienen las redes para acceder a todos los sitios web por distintos motivos.
La mayor parte de la información encontrada en la Internet Profunda está enterrada en sitios generados dinámicamente y para los motores de búsqueda tradicionales es difícil hallarla.
Existen muchos mitos acerca de la Internet Profunda. No es una región prohibida y mística del Internet, tampoco la tecnología relacionada con esta es malévola. Es un lugar específico del Internet que se distingue por el anonimato. Nada que se haga en esta zona puede ser asociado con la identidad de uno, a menos que uno lo desee. Fiscales y Agencias Gubernamentales han calificado a la Internet Profunda como un refugio para la delincuencia, debido al contenido ilícito que se encuentra en ella.
En ella también se alberga lo ahora conocido como (AIW), por sus siglas en inglés, “the Academic Invisible Web” (La Web Académica Invisible, y se refiere a todas las bases de datos que contienen avances tecnológicos, publicaciones científicas y material académico en general).
Causas
La principal causa de la existencia de la Internet Profunda es la imposibilidad de los motores de búsqueda (Google,Yahoo, Bing, etc.) de encontrar o indexar gran parte de la información existente en Internet. Si los buscadores tuvieran la capacidad para acceder a toda la información, entonces la magnitud de la "Internet Profunda" se reduciría casi en su totalidad. No obstante, aunque los motores de búsqueda pudieran indexar la información de la Internet Profunda, esto no significaría que esta dejará de existir, ya que siempre existirán las páginas privadas.
Los motores de búsqueda no pueden acceder a la información de estas páginas. Solo determinados usuarios, aquellos con contraseña o códigos especiales, pueden hacerlo.
Tamaño
El contenido que puede ser hallado dentro de la Internet Profunda es muy amplio. Se estima que la Internet Profunda es 500 veces mayor que la Internet Superficial, siendo el 95% de esta información públicamente accesible.
La Internet se ve dividida en dos ramas: la Profunda y la Superficial. La Internet Superficial se compone de páginas estáticas o fijas, mientras que la Web Profunda está compuesta de páginas dinámicas. La páginas estáticas no dependen de una base de datos para desplegar su contenido, sino que residen en un servidor en espera de ser recuperadas, y son básicamente archivos HTML, cuyo contenido nunca cambia.
Todos los cambios se realizan directamente en el código y la nueva versión de la página se carga en el servidor. Estas páginas son menos flexibles que las páginas dinámicas. Las páginas dinámicas se crean como resultado de una búsqueda de base de datos. El contenido se coloca en una base de datos y se proporciona solo cuando lo solicite el usuario.
Se estima que la información que se encuentra en la Internet Profunda es de 7,500 terabytes, lo que equivale a aproximadamente 550 billones de documentos individuales. El contenido de la Internet Profunda es de 400 a 550 veces mayor de lo que se puede encontrar en la Internet Superficial. En comparación, se estima que la Internet Superficial contiene solo 19 terabytes de contenido y un billón de documentos individuales.
En 2010 existían más de 200, 000 sitios en la Internet Profunda.
La ACM, por sus siglas en inglés (Association for Computing Machinery), publicó en 2007 que Google y Yahoo indexaban el 32 % de los objetos de la Internet Profunda, y MSN tenía la cobertura más pequeña con el 11 %. Sin embargo, la cobertura de lo tres motores era de 37 %, lo que indicaba que estaban indexando casi los mismos objetos.
Se prevé que alrededor del 95% del Internet es Internet Profunda, también la llaman Invisible u Oculta. La información que alberga no siempre está disponible para su uso. Por ello, se han desarrollado herramientas como buscadores especializados para acceder a ella.
Denominación
Bergman, en un artículo semanal sobre la Web Profunda, publicado en el Journal of Electronic Publishing, mencionó que Jill Ellsworth utilizó el término "la Web Invisible" en 1994 para referirse a los sitios web que no están registrados por algún motor de búsqueda.
Bergman citó un artículo de 1996 de Frank García:
"Otro uso temprano del término Web Invisible o Web Profunda fue por Bruce Monte y Mateo B. Koll de Personal Library Software, en una descripción de la herramienta @ 1 de Web Profunda, en un comunicado de prensa de diciembre de 1996."
La importancia potencial de las bases de datos de búsqueda también se reflejó en el primer sitio de búsqueda dedicado a ellos: el motor AT1, que se anunció con bombos y platillos a principios de 1997. Sin embargo, PLS, propietario de AT1, fue adquirida por AOL en 1998, y poco después el servicio AT1 fue abandonado.
El primer uso del término específico de Web Profunda, ahora generalmente aceptado, ocurrió en el estudio de Bergman de 2001, mencionado anteriormente.
Por otra parte, el término Web Invisible se dice que es inexacto porque:
- Muchos usuarios asumen que la única forma de acceder a la Web es consultando un buscador.
- Alguna información puede ser encontrada más fácilmente que otra, pero esto no quiere decir que esté invisible.
- La Web contiene información de diversos tipos que es almacenada y recuperada en diferentes formas.
- El contenido indexado por los buscadores de la Web es almacenado también en bases de datos y disponible solamente a través de las interrogaciones del usuario, por tanto, no es correcto decir que la información almacenada en la bases de datos es invisible.
Rastreando la Internet Profunda
Los motores de búsqueda comerciales han comenzado a explorar métodos alternativos para rastrear la Web Profunda. El Protocolo del sitio (primero desarrollado e introducido por Google en 2005) y OAI son mecanismos que permiten a los motores de búsqueda y otras partes interesadas descubrir recursos de la Internet Profunda en los servidores web en particular. Ambos mecanismos permiten que los servidores web anuncien las direcciones URL que se puede acceder a ellos, lo que admite la detección automática de los recursos que no están directamente vinculados a la Web de la Superficie.
El sistema de búsqueda de la Web Profunda de Google pre-calcula las entregas de cada formulario HTML y agrega a las páginas HTML resultantes en el índice del motor de búsqueda de Google. Los resultados surgidos arrojaron mil consultas por segundo al contenido de la Web Profunda. Este sistema se realiza utilizando tres algoritmos claves:
- La selección de valores de entrada, para que las entradas de búsqueda de texto acepten palabras clave.
- La identificación de los insumos que aceptan solo valores específicos (por ejemplo, fecha).
- La selección de un pequeño número de combinaciones de entrada que generan URLs adecuadas para su inclusión en el índice de búsqueda Web.
A pesar de que son muchos los servicios y programas para acceder a la Web Profunda, el software más popular es Tor (The Onion Router), pero existen otras alternativas como I2P y Freenet.9
TOR es un proyecto diseñado e implementado por la Marina de los Estados Unidos, posteriormente fue patrocinado por la EFF (Electronic Frontier Foundation, una organización en defensa de los derechos digitales). Actualmente subsiste como TOR Project, una organización sin ánimo de lucro, galardonada en 2011 por la Free Software Foundation por permitir que millones de personas en el mundo tengan libertad de acceso y expresión en Internet, manteniendo su privacidad y anonimato. A diferencia de los navegadores de Internet convencionales, Tor le permite a los usuarios navegar por la Web de forma anónima. Tor es descargado de 30 millones a 50 millones de veces al año. Hay 800,000 usuarios diarios de Tor y un incremento del de 20 % en el 2013. Tor puede acceder a 6,500 sitios web ocultos.
Cuando se ejecuta el software de Tor para acceder a la Internet Profunda, los datos de la computadora se cifran en capas. El software envía los datos a través de una red de enlaces a otros equipos y lo va retransmitiendo quitando una capa antes de retransmitirlo de nuevo. Esta trayectoria cambia con frecuencia. Tor cuenta con más de 4.000 retransmisiones. Los datos cifrados pasan a través de tres de ellos. Una vez que la última capa de cifrado es despojado se conecta a la página web que se desea visitar. Mercados ilegales están alojados en servidores que son exclusivos para usuarios de Tor. En estos sitios se pueden encontrar drogas, armas o, incluso, asesinos a sueldo. Se utiliza la moneda digital llamada Bitcoin, que tiene sus orígenes en 2009, pero que se ha vuelto todo un fenómeno desde 2012, intercambiada a través de billeteras digitales entre el usuario y el vendedor, lo que hace que sea prácticamente imposible de rastrear.
Recursos de la Internet Profunda
Los recursos de la Internet Profunda pueden estar clasificados en una de las siguientes categorías:
- Contenido de Acceso limitado: los sitios que limitan el acceso a sus páginas de una manera técnica (por ejemplo, utilizando el estándar de exclusión de robots o captcha, que prohíben los motores de búsqueda de la navegación por y la creación de copias en caché).
- Contenido Dinámico: Las páginas dinámicas que devuelven respuesta a una pregunta presentada o acceder a través de un formulario, especialmente si se utilizan elementos de entrada en el dominio abierto como campos de texto.
- Contenido No Vinculado: páginas que no están conectadas con otras páginas, que pueden impedir que los programas de rastreo web tengan acceso al contenido. Este material se conoce como páginas sin enlaces entrantes.
- Contenido Programado: páginas que solo son accesibles a través de enlaces producidos por JavaScript, así como el contenido descargado de forma dinámica a partir de los servidores web a través de soluciones de Flash o Ajax.
- Sin contenido HTML: contenido textual codificado en multimedia (imagen o video) archivos o formatos de archivo específicos no tratados por los motores de búsqueda.
- Web privada: los sitios que requieren de registro y de una contraseña para iniciar sesión.
- Web contextual: páginas con contenidos diferentes para diferentes contextos de acceso (por ejemplo, los rangos de direcciones IP de clientes o secuencia de navegación anterior).
0 Comentarios